网络舆情学习汇报
什么是网络舆情
-
百度百科:网络舆情是指在互联网上流行的对社会问题不同看法的网络舆论,是社会舆论的一种表现形式,是通过互联网传播的公众对现实生活中某些热点、焦点问题所持的有较强影响力、倾向性的言论和观点。
“网络舆情是以网络为载体,以事件为核心,广大网民情感、态度、意见、观点的表达、传播与互动,以及后续影响力的集合。” -
网络舆情的涵义及特征
我国学者根据自身的学科背景与个人认知从不同角度给出了网络舆情的定义,因而网络舆情的概念呈现出百花齐放的局面。而主流的网络舆情定义可以划分为两种:一种是基于公众的社会政治态度,另一种则基于社情民意的集合反映。网络舆情是与互联网技术的发展相伴而生的,网络与舆情的结合注定了其与传统舆情存在着区别。 网络舆情具有互联网的鲜明特点,如匿名性,互联网环境中每个人都可以选择匿名发表言论;互动性,网络社会当中我们每个人都可以随时随地与他人进行交流与互动;偏差性,网络虚拟环境下各种言论甚嚣尘上,往往会出现失真信息甚至是网络谣言。 而当前我国对于网络舆情特征的研究主要有 3 种视角:工具性视角、系统性视角、要素及过程视角(如表1) 。
-
网络舆情研究方法
- 定性研究: 定性研究也称质性研究,是社会科学研究中一种基本的研究范式,定性研究中常常会使用比较、分类、归纳、分析等方法,在网络舆情的研究中,定性研究也是一种较为常用的研究方法。 如对各种概念进行辨析,对网络舆情的特征进行归纳,对现有的理论进行分类、根据经验提出应对策略等等。
- 定量研究: 定量研究方法是人们在科学探索过程中形成的一种较为精确的的语言,这种语言能够 较大程度上扩展定性方法的能力。网络舆情具有复杂性、非线性等特点,因此在网络舆情的研究当中大量使用了定量方法,尤其表现在指标体系的构建、舆情热点或等级的评判体系、舆情分析及预警模型的建立等方面。
- 仿真研究: 网络舆情的研究是一个跨学科研究领域,尤其伴随着信息技术的不断发展与成熟,计算实验的仿真分析作为一种较为有效的研究方法在网络舆情研究中的使用越来越广泛。 仿真研究方法是以计算机技术、信息技术及数学方法为基础,在虚拟环境中模拟现实可能发生的状态或对未来趋势进行预测。 网络舆情的仿真研究主要表现在网络舆情的传播及演化机理、舆情相关主体间的内在联系及相互作用、网络舆情的预警与导控3个方面。
网络舆情现状分析
-
《第39次中国互联网络发展状况统计报告》显示,至 2016 年 12 月,中国网民规模达 7. 31 亿,手机网民规模达 6. 95 亿,互联网普及率为 53. 2%,网络舆情的影响力和影响范围逐渐扩大。 由此,以“ 网络舆情为主题在 CNKI 中检索共有文献 15 406 篇,2005年开始出现直接相关文献,2007 年后相关研究迅猛发展,预计 2017 年将突破 3000 篇( 见表1) 。
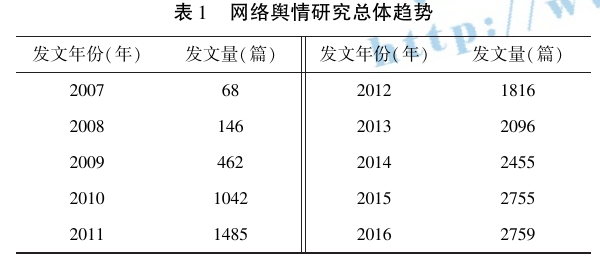
-
发文量趋势:
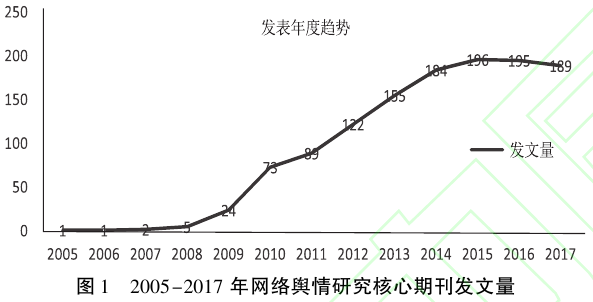
-
研究热点:图 2 涵盖了近 13 年来我国网络舆情研究的热点问题,其中不同大小的圆圈直观地表达了热点主题的主次,圆圈越大,研究的热度越高。 图中最大的关键节点是 “ 网络舆情冶,其余的关键节点依次为“ 突发事件冶 、“ 大数据冶 、“ 舆情分析冶 等等。
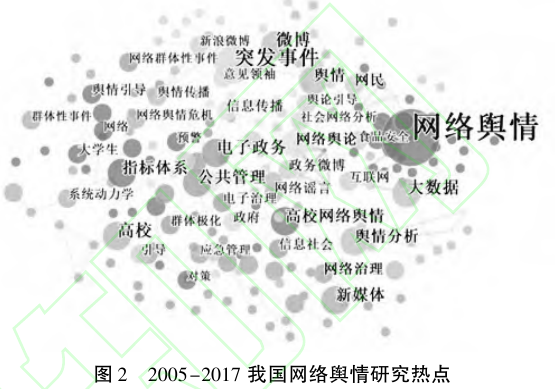
-
主题变迁趋势:见图3
-
网络舆情研究早期(2005 - 2008) :这一时期为我 国网络舆情研究的萌芽阶段,网络舆情研究发文量较少,研究主题词主要包括 “ 网络舆情冶 、“ 网络舆论冶 、“ 网络谣言冶 等,主要侧重于网络舆情相关概念及基础理论的研究。
-
网络舆情研究中期(2009 -2014) :这一时期为我 国网络舆情研究的发展阶段,文献数量相比于研究早期大幅上升,研究主题则主要包括“ 突发事件冶 、“ 指标体系冶 、“ 社会网络分析冶 等,主要侧重于网络舆情的分析与引导方法研究。
-
网络舆情研究近期(2015 - 2017) :这一时期为我 国网络舆情研究的成熟阶段,总体发文量呈略微下降趋势,并最终趋于稳定。这一时期网络舆情的研究主题主要包括“ 新媒体冶 、“ 政务微博冶 、“ 大数据冶等,主要侧重于新兴信息技术在网络舆情中的应用,尤其凸显了政府运用信息技术进行网络舆情治理。

-
结论:我国网络舆情研究主要集中在三个方面,且研究层次逐步深入。
第一,网络舆情的基础理论研究。
第二,网络舆情研究方法的探究。
第三,网络舆情的实践及应用研究(如图4所示)。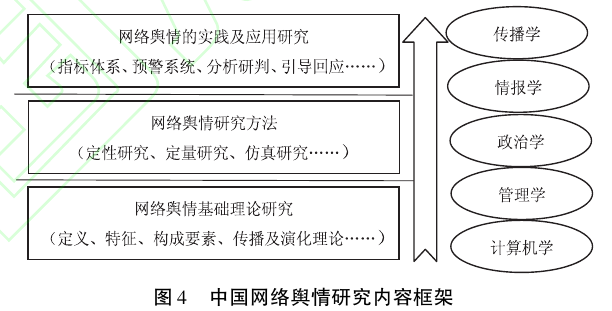
-
网络舆情相关文献
-
中国网络舆情研究13年(2005-2017)理论-方法与实践 李明
-
基于首发信息的微博舆情热度预测模型 连芷萱
-
大数据环境下多媒体网络舆情传播要素及运行机理研究
-
基于决策树的网络舆情类型识别模型研究 覃玉冰
-
基于皮尔逊相关系数的网络舆情评估指标体系构建研究 覃玉冰
-
基于舆情大数据的网民情感_衰减_转移_模型与实证研究 夏一雪
-
网络舆情信息的综合评价指标体系构建与模糊评判模型 李文杰
-
基于模糊神经网络的微博舆情趋势预测方法 胡悦
-
基于决策树的网络伪舆情识别研究 赵静娴
学习论文:基于首发信息的微博舆情热度预测模型
摘要:通过构建数学模型,研究大数据背景下微博舆情热度预测问题
- 方法:分析大数据背景下的微博舆情的首发信息特征定义首发信息影响系数,建立微博首发信息热度预测方程模型
- 结论:利用百度指数,清博舆情等软件,研究47个微博舆情实例分析模型特征,并用6个微博舆情案例验证模型,得出该模型根据微博首发信息的少量数据而得到较为准确的预测结果.研究成果有利于政府面对复杂微博舆情时做到”心中有数”.
现状分析
- 据CNNIC发布的40次《中国互联网发展状况统计报告》显示,截至到 2017 年 8 月,中国网民规模达到 7.51 亿人。移动互联网已成为公众获取信息和传播交流的重要媒介。同时,在人民网公布的舆情指数排名前20的网络热点事件中,有5事件由微博首发,占20% 以上。
- 当前针对舆情的预测模型主要有三类,基于统计学的舆情预测模型、基于智能机器算法的微舆情预测模型和基于社会学理论仿真的舆情预测模型。
- 本文利用Citespace软件对网络舆情预测的334篇文章关键词进行聚类整理,如图 1所示,目前国内应急管理领域的研究前沿主要集中在 3个部分:
- 一是以“自回归模型”、“指数平滑模型”等为主的基于统计学的舆情预测模型(A区);
- 二是以“灰色理论模型”、“神经网络模型”等为主的基于智能机器算法的舆情预测模型(B区);
- 三是以“系统动力学”“社会网络分析”等为主的基于社会学理论仿真的舆情预测模型(C区).
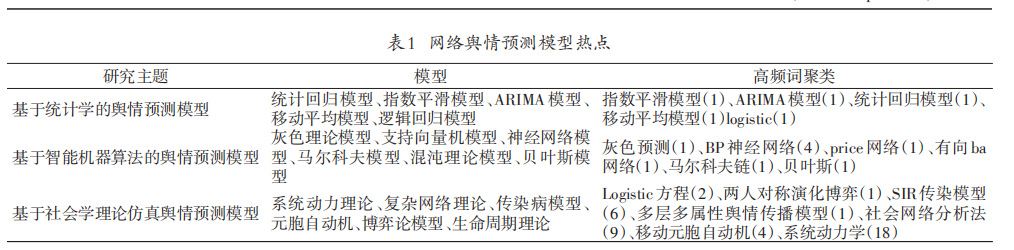
- 基于统计学的舆情预测模型热点主要涉及:①自回归模型:杨畅等认为网络舆情演变规律和酶促反应机理相似,构建统计回归模型研究其演变规律。②逻辑回归模型:赵丽娟利用logistic曲线对广西铬污染舆情事件的演进机理进行仿真,得到很好的效果。
- 基于智能机器算法的舆情预测模型热点主要涉及:①灰色理论模型:杜智涛等认为灰色系统理论可以在信息不对称的环境下通过系统的发展变化而分析舆情的整体演变态势.②支持向量机模型:曾振东针对支持向量模型来提高对舆情演化仿真的精度。
- 基于社会学理论仿真的舆情预测模型热点主要涉及:③传染病模型:朱恒民等提出基于BA 网络的舆情传播演化的 SIRS 模型,并通过实验验证衍生话题对舆情传播过程的影。 ④元胞自动机:宋姜等通过元细胞自动机模型来研究不同观点网民之间对网络舆情演进的影响.
- 目前,国内外的方法和研究虽然从不同的角度对网络舆情预测及应对进行了丰富的探索,但是从实战的角度上讲,微博舆情爆发性强、扩散速度极快,所以需要在舆情潜伏期内,针对少量数据便做出精准预测,迅速处理。而目前研究的网络舆情预测方法多是基于舆情发展整体过程的数据来探究其发展规律,研究主要集中在舆情的扩散期,基于潜伏期内微博反映出来的少量信息而展开预测的模型较少,为丰富这方面的研究,本文针对微博舆情的首发信息建立风险评估指标体系,从而基于首发信息对突发事件未来的舆情走向和风险进行评估、预测。
影响因素
- 本文基于信息学角度,网络空间的信息扩散是信息随着时间从信源逐级逐层地传播至信宿并被信宿接受、采纳和利用,使得信息的覆盖由一点弥漫至整个空间的过程。而微博舆情的传播也可以看做网络空间信息传播的一种。所以微博舆情也可以描述成微博用户转发信息同时被其他用户采纳的过程。 微博信息扩散是微博信息通过转发、话题参与等手段,在以微博互粉而形成的虚拟人际关系网上不断扩大采纳应用范围的过程。它以扩散的行为参与者为基础,以微博平台为支撑,以利益驱动和信息势差为动力,是一个涉及众多因素的复杂过程。本文对微博的信息扩散问题主要从信源特征、信息格式、信宿偏好三个角度来分析微博首发信息对舆情扩散的影响因素。
- 信源特征对于微博舆情影响的假设:
- H1 微博信息的首发用户身份会正向影响微博舆情的热度
- H2 微博信息的首发用户粉丝数会正向影响微博舆情热度
- H3 信源信宿在差异信息上具有的信息位势差,是信源具有扩散能力的基础,所以信源信息丰富便具有了信息传播的条件
- H4 微博信息的首发用户关注量会正向影响微博舆情热度。
- H5 微博信息的首发用户的发帖数会正向影响微博舆情热度
- 信息格式对于微博舆情影响的假设:
- H6 首发信息博文长度会正向影响微博舆情热度。
- H7 首发信息博文内嵌的多样化形式会正向影响微博舆情度
- 信宿需求对于微博舆情影响的假设:
- H8 首发信息在第一天的转、评、赞量会正向影响微博舆情热度
本文主要从信源特征、信息形式和信宿需求三个视角出发,提出微博舆情传播影响因素的相关假设和模型,并选择合适的方法收集、分析数据,对模型进行验证。
模型构建
- 预警模型由四部分构成,风险因素指标体系、微博舆情案例库、Logistic模型、风险等级预警模型。
- 第一步,通过分析确定风险因素,根据风险因素以及案例指标特性构建风险预警指标体系。
- 第二步,收集舆情信息,构建微博舆情案例库。由于微博舆情爆发迅速,本文以24小时为预测事件范围。
- 第三步,以24小时内舆情浏览量最高者为舆情饱和状态,确定预警等级,并对案例库数据做logistic 回归,得出关系式。
- 第四步,将24小时后,需要进行预测的实时案例的数据标准化后代回第三步得出关系式,反推相应的预警等级,从而达到预警目的。
- 指标体系的构建:
本文以上文总结的微博首发信息特征要素为影响因素,以浏览量作为微博舆情热度的表征指标,构建通过微博首发信息的少量数据而进行舆情热度的预测模型
依据样本数据特征,将假设H1提炼出博主身份一个定性指标,细分为微博V认证、微博会员、微博达人、普通用户四个标准。,将假设H2-H5提炼出粉丝量、关注量、历史发帖数三个定量指标。将假设H6、H7提炼出标题长度、博文长度、包含图片、小视频、链接等五个指标。将假设H8提炼出首条信息转发、评论、点赞量三个指标(见表1)。

-
logistic预测模型构建: Logistic模型。Logistic 模型的一般形式为\(y=\dfrac{K}{1 + a\cdot e^{bx}}\). 式中的y为模型的输出,K、b、a 为模型的参数(K一般称为饱和参数或饱和值,b一般称为相对增长速率,a一般称为系数),e≈2.71828(为常数)x一般为时序)为模型的输入。 将该模型变换得到线性模型\(ln(\dfrac{K}{y}-1)=ln a + bx\),从而通过直线回归求得模型各个参数。在求得参数后,将新的案例变量代入该线性模型,转化至logistic模型,从而得到新案例y的模型输出。
其中,设y为单条案例的关注量,x为影响舆情案例热度的各个因素,饱和系数K为舆情案例库内案例最高关注量,$ln \alpha$为案例库舆情的基础热度,b为影响舆情热度的各个要素系数。本文主要对该模型的系数值进行分析,得出系数后,将新案例数据代入模型反求y值,确定预警等级.
- 微博舆情风险评估预警级别:
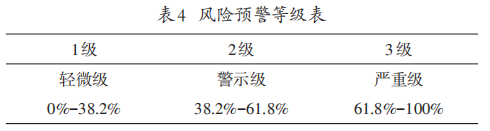
微博舆情风险评估预警级别分为轻微级、警示级、严重级、高危级 4 个等级,分别用1、2、3、4表示。首先根据案例库中得出的各个指标系数B,得出预测函数,然后将新案例的指标代入该函数计算舆情热度比值,将舆情热度比值与表4进行比对,以此确定各个因素其对应的警戒级别。
根据清华大学刘建明的研究,将微博舆情预警等级分为三级,1级为轻微级,可以选择忽略。2级为警示级,需要相关部门高度重视,严格监控该条舆情走势。3级为严重级,相关部门迅速对该条舆情做出回应,将舆情抑制在潜伏期内。
实证分析
- 构建舆情预测案例库
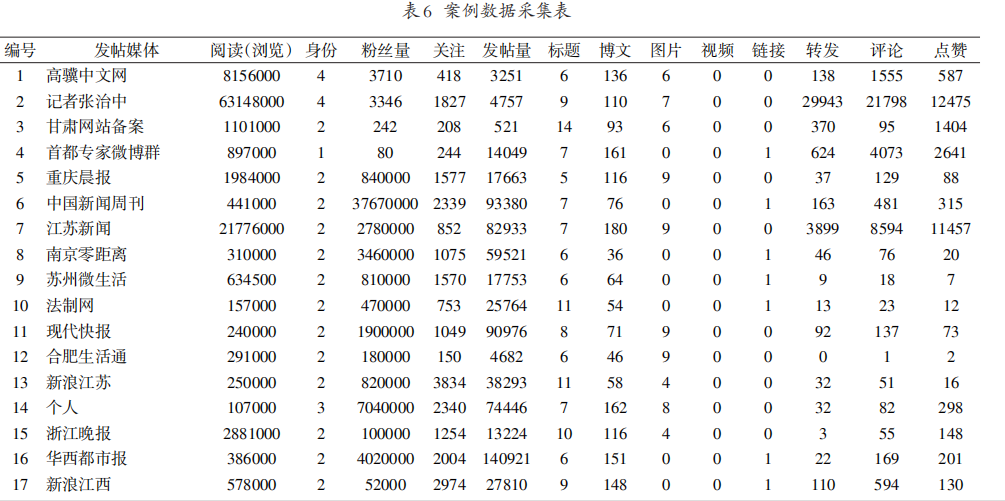
本文以新浪微博的社会类话题为例,采用JAVA编程及蜘蛛爬虫方式采集获取样本数据,从原创微博出发遍历获取如下字段数据:
用户ID、用户等级、粉丝量、关注量、信息内容、转发评论点赞数等数据,建立社会类舆情案例库。
截止到 2017 年 3 月 27 日 21: 00,从 47 个舆情话题的1218条原创微博出发,获取共获取话题类别、主持媒体ID、帖子数、主持媒体粉丝数、信息内容、转评赞量、浏览量等8类数据。
在数据清洗和处理阶段,主要进行如下工作: 去除重复值和缺失值;基于信息内容字段图片、视频、语音、文本、表情等内容形式数量,相应信息格式偏好字段以 0、1 赋值;将清洗后的数据依据研究变量公式进行数值计算;计算舆情热度比值;最终构建了47行13列的微博舆情预警案例库矩阵。 - 本文以天为单位进行预测,选取了新浪微博里2017年3月27日发生的47个社会类微博舆情案例进行风险预警分析选择27日舆情热度值最高的“泸州太伏中学学生死亡”事件作为参照 ,确定预警等级。
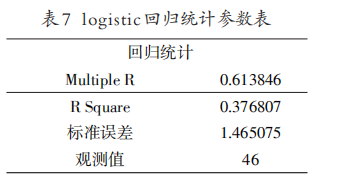
把该事件相关微博的13个指标进行logistic分析,得到13个指标与浏览量的模型表达式,如表7、表8所示。
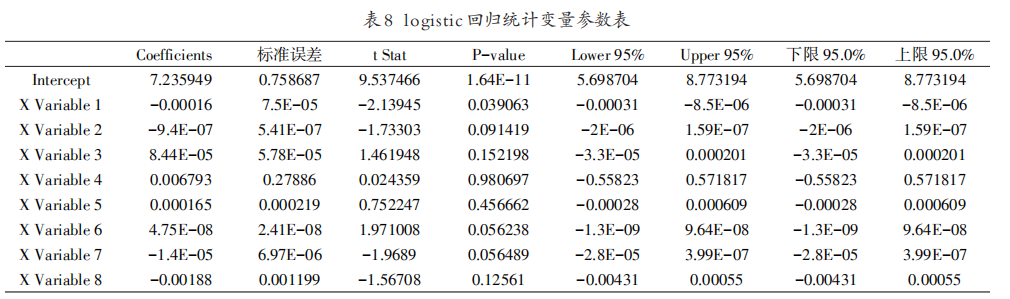
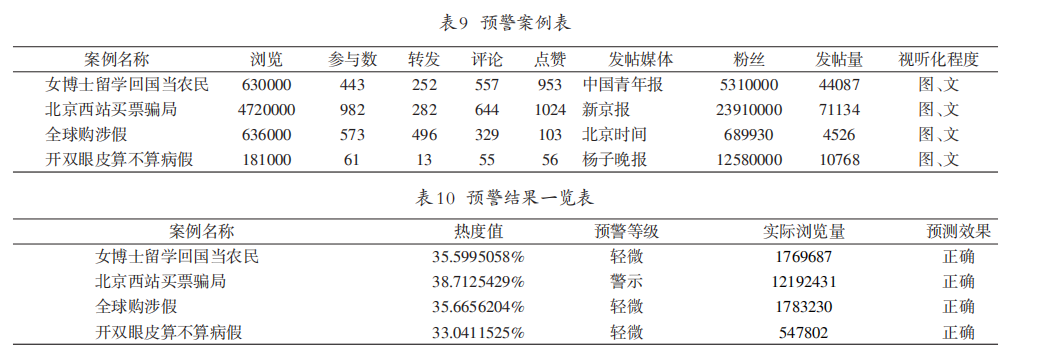
- 利用3月27 日舆情案例(如表9所示)构建的logistic模型,预测28日的热度趋势预测值,并与真实数据对比,结果如表10所示。分析预测区间和实际区间可知,logistic模型用于预测微博舆情热度准确率达到80%,说明该模型有效。
主要结论
- 优点:首先,对微博舆情的预测,本文提供了一种新的预测思路,本文从信息传播的角度上提炼单条微博首发信息要素,定性与定量相结合地对微博舆情首发信息进行指标体系的构建,并通过与新浪微博的预测热度值和实际浏览量互相对照,证明了该模型确实有效.
- 缺点:
- 首发信息提取不够全面。
- 由于篇幅与人力的限制,实证案例仅采集了新浪微博24小时内的上热搜榜单的案例数据,该模型的预测精度与其案例库的大小有关。在实战应用中,应完善数据库的构建。