情感分析
1 概述
情感分析是自然语言处理中常见的场景,比如淘宝商品评价,饿了么外卖评价等,对于指导产品更新迭代具有关键性作用。通过情感分析,可以挖掘产品在各个维度的优劣,从而明确如何改进产品。比如对外卖评价,可以分析菜品口味、送达时间、送餐态度、菜品丰富度等多个维度的用户情感指数,从而从各个维度上改进外卖服务。
选特定主题、话题做情感分析,话题不一样,数据就不一样,比如:x事件情感分析,xxx电影评论情感分析,xxx电商评论情感分析,xxx地旅游评论情感分析等等。
情感分析可以采用基于情感词典的传统方法,也可以采用基于深度学习的方法。
2 基于情感词典的传统方法
2.1 基于词典的情感分类步骤
基于情感词典的方法,先对文本进行分词和停用词处理等预处理,再利用先构建好的情感词典,对文本进行字符串匹配,从而挖掘正面和负面信息。如下图
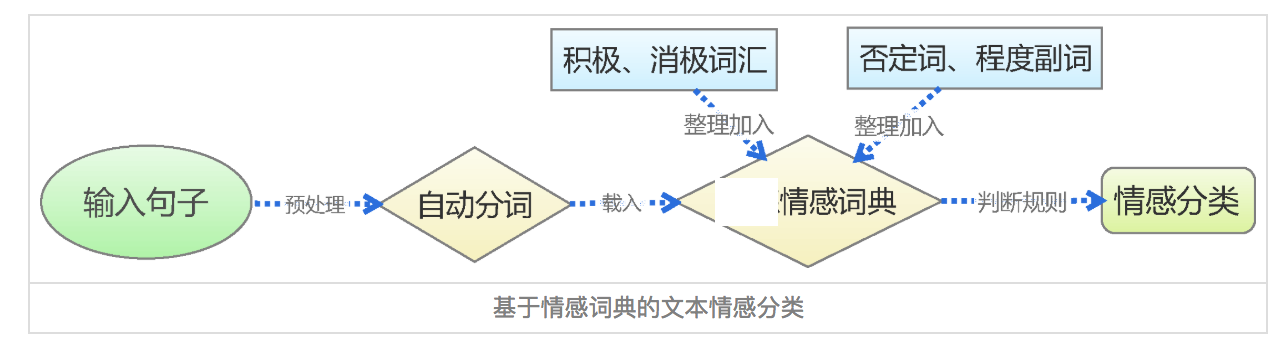
2.2 情感词典
情感词典包含正面词语词典、负面词语词典、否定词语词典、程度副词词典等四部分。如下图
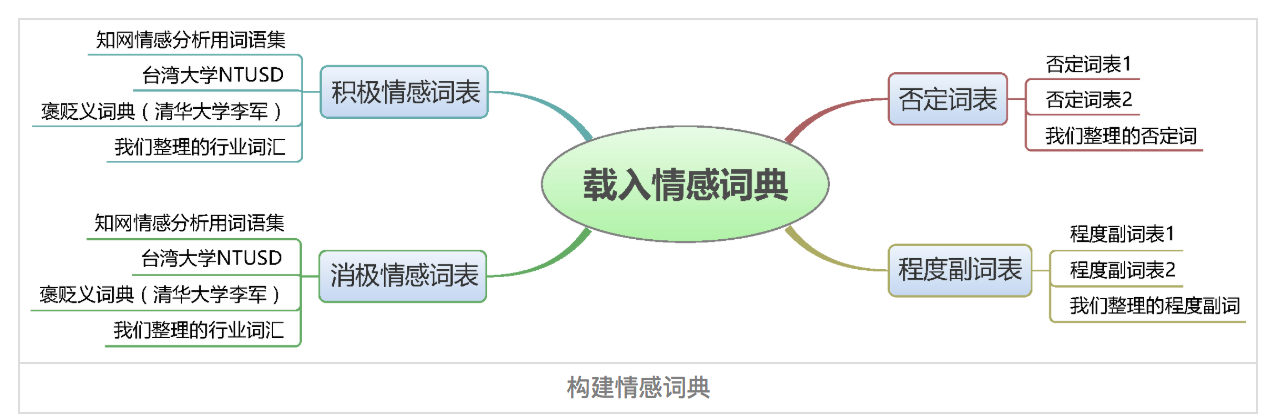
词典包含两部分,词语和权重,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
正面:
很快 1.75
挺快 1.75
还好 1.2
很萌 1.75
服务到位 1
负面:
无语 2
醉了 2
没法吃 2
不好 2
太差 5
太油 2.5
有些油 1
咸 1
一般 0.5
程度副词:
超级 2
超 2
都 1.75
还 1.5
实在 1.75
否定词:
不 1
没 1
无 1
非 1
莫 1
弗 1
毋 1
情感词典在整个情感分析中至关重要,所幸现在有很多开源的情感词典,如BosonNLP情感词典,它是基于微博、新闻、论坛等数据来源构建的情感词典,以及知网情感词典等。当然我们也可以通过语料来自己训练情感词典。
2.3 情感词典文本匹配算法
基于词典的文本匹配算法相对简单。逐个遍历分词后的语句中的词语,如果词语命中词典,则进行相应权重的处理。正面词权重为加法,负面词权重为减法,否定词权重取相反数,程度副词权重则和它修饰的词语权重相乘。如下图
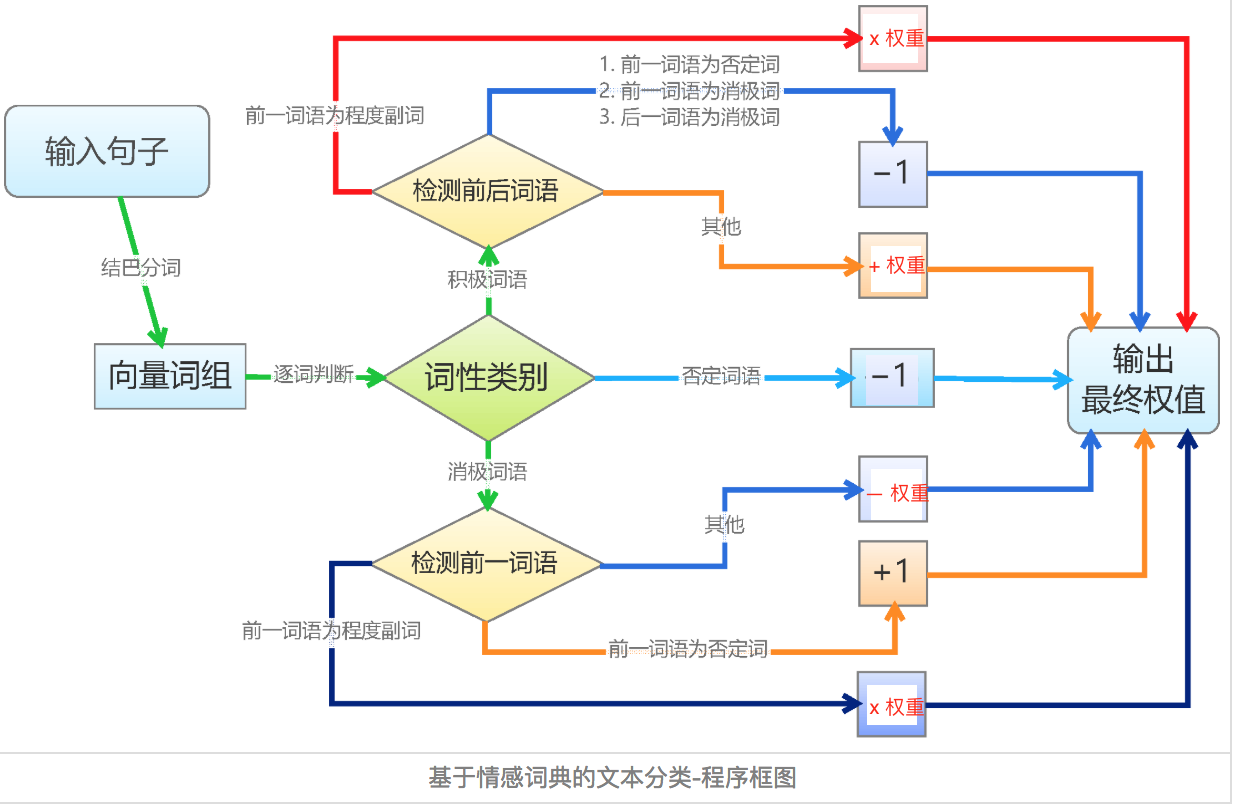
利用最终输出的权重值,就可以区分是正面、负面还是中性情感了。
2.4 缺点
基于词典的情感分类,简单易行,而且通用性也能够得到保障。但仍然有很多不足
- 精度不高。语言是一个高度复杂的东西,采用简单的线性叠加显然会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
- 新词发现。对于新的情感词,比如给力,牛逼等等,词典不一定能够覆盖
- 词典构建难。基于词典的情感分类,核心在于情感词典。而情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,在分析外语方面会有很大限制。
2.5 情感分析教程:
Python是关于数据分析,机器学习和NLP(包括情感分析)教程的最常用编程语言,但R正在迅速赶上,特别是针对数据科学家和统计学家的教程。
-
使用python对Top100 Subreddits进行情感分析
首先解释如何使用Beautiful Soup,这是用于网页抓取的最流行的Python库之一,以便从网页中爬取数据。作者使用这个库来抓取这个网页来获取前100个subreddits。一旦获得subreddits的名称,他就使用Praw库与RedditAPI进行交互并从这些subreddit中提取评论。 -
使用NLTK来对Tweets进行情感分析
使用自然语言处理工具NLTK训练能够预测新推文情感的分类器。首先,作者解释了如何从预定义的正面和负面推文集中提取特征。 这些特征是一系列不同的单词,可用于表示每条推文,是训练分类器的关键部分。然后,您将学习如何准备包含标签的训练数据。 最后,他继续训练Naive Bayes分类器,这是一种简单但功能强大的算法,特别适合自然语言处理问题。训练分类器结束后,作者继续解释如何使用这个模型对新的推文进行分类。 -
使用Scikit-learn和Jupyter Notebook来对Tweets进行情感分析 Scikit-learn是一种简单而有效的数据分析工具,最常用于数据分类,回归和聚类问题。因为它功能强大但每个人都可以掌握,所以它是机器学习中最常用的库之一。它解释了如何训练逻辑回归模型用于情绪分析。 首先介绍如何正确设置我们的环境,包括jupyter notebook,这是一个允许快速原型设计,以及共享与数据相关的项目,的一个应用。之后,作者继续解释如何使用scikit-learn准备和向量化我们的数据。最后,它训练了一个线性分类器,并展示如何评估模型,以及计算模型的准确度。
2.5.1 研究文献
与情感分析相关的论文:
关于情绪分析的文献很多; 有超过55,700篇学术文章,论文,论文,书籍和摘要。
以下是情绪分析中最常被引用和阅读的论文:
Opinion mining and sentiment analysis (Pang and Lee, 2008)
Recognizing contextual polarity in phrase-level sentiment analysis (Wilson, Wiebe and Hoffmann, 2005)
Sentiment analysis and subjectivity (Liu, 2010)
A survey of opinion mining and sentiment analysis (Liu and Zhang, 2012)
Sentiment analysis and opinion mining (Liu, 2012)
与情感分析相关的书:
刘冰是该领域的杰出人物,并撰写了一本对于那些开始研究情绪分析的人来说,非常好的书。 他以一种高度技术性,可理解的方式解释情绪分析,做得非常出色。 这本书涵盖了情感分析的不同方面,包括应用,研究,使用监督和无监督学习的情感分类,句子主观性,基于方面的情感分析等。
2.5.2 情感分析APIs:
开源库: 在开源库中,Python或Java之类的编程语言,因为它们具有强大的数据科学社区,数据科学的开源库,包括自然语言处理。 为了成功使用下面的库,你应该具有足够的机器学习和编程先验知识。
Python情感分析APIs Python是数据科学领域的顶级编程语言之一,它具有强大的社区和大量的NLP模型。 以下是几个例子:
Scikit-learn是机器学习的首选库,具有用于文本向量化的工具。 利用频率或tf-idf文本向量化器之类的工具,训练一个分类器非常简单。 Scikit-learn实现了支持向量机,朴素贝叶斯和Logistic回归等模型; NLTK一直是Python的传统NLP库。 它有一个活跃的社区,除了为NLP提供低级功能外,还提供了训练机器学习分类器的可能性; SpaCy是另一个NLP库,社区正在不断壮大。与NLTK一样,它为NLP提供了一组强大的底层函数,并支持训练文本分类器。 随着深度学习越来越火,过去几年中,人们开发了各种新的数据科学库,支持NLP应用。 一些出名的: TensorFlow :它由Google开发,提供了一套用于构建和训练神经网络的底层工具。 还支持文本矢量化,包括传统的词频和更高级的词嵌入。 Keras提供有用的抽象来处理多种神经网络类型,如递归神经网络(RNNs)和卷积神经网络(CNN),并轻松堆叠神经元层。 Keras可以在Tensorflow或Theano之上运行。 并且它为文本分类提供了有用的工具。 PyTorch是最近的深度学习框架,由Facebook,Twitter,Nvidia,Salesforce,斯坦福大学,牛津大学和优步等知名组织提供支持。 它迅速发展了一个强大的社区。
3 基于深度学习的算法
近年来,深度学习在NLP领域内也是遍地开花。在情感分类领域,我们同样可以采用深度学习方法。基于深度学习的情感分类,具有精度高,通用性强,不需要情感词典等优点。
3.1 基于深度学习的情感分类步骤
基于深度学习的情感分类,首先对语句进行分词、停用词、简繁转换等预处理,然后进行词向量编码,然后利用LSTM或者GRU等RNN网络进行特征提取,最后通过全连接层和softmax输出每个分类的概率,从而得到情感分类。

3.2 代码示例
下面通过代码来讲解这个过程。2018年AI Challenger细粒度用户评论情感分析比赛中的代码。项目数据来源于大众点评,训练数据10万条,验证1万条。分析大众点评用户评论中,关于交通,菜品,服务等20个维度的用户情感指数。分为正面、负面、中性和未提及四类。代码在验证集上,目前f1 socre可以达到0.62。
3.2.1 分词和停用词预处理
数据预处理都放在了PreProcessor类中,主函数是process。步骤如下:
读取原始csv文件,解析出原始语句和标注
错别字,繁简体,拼音,语义不明确等词语的处理
stop words停用词处理
分词,采用jieba分词进行处理。分词这儿有个trick,由于分词后较多口语化的词语不在词向量中,所以对这部分词语从jieba中del掉,然后再进行分词。直到只有为数不多的词语不在词向量中为止。
构建词向量到词语的映射,并对词语进行数字编码。这一步比较常规。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
class PreProcessor(object):
def __init__(self, filename, busi_name="location_traffic_convenience"):
self.filename = filename
self.busi_name = busi_name
self.embedding_dim = 256
# 读取词向量
embedding_file = "./word_embedding/word2vec_wx"
self.word2vec_model = gensim.models.Word2Vec.load(embedding_file)
# 读取原始csv文件
def read_csv_file(self):
reload(sys)
sys.setdefaultencoding('utf-8')
print("after coding: " + str(sys.getdefaultencoding()))
data = pd.read_csv(self.filename, sep=',')
x = data.content.values
y = data[self.busi_name].values
return x, y
# todo 错别字处理,语义不明确词语处理,拼音繁体处理等
def correct_wrong_words(self, corpus):
return corpus
# 去掉停用词
def clean_stop_words(self, sentences):
stop_words = None
with open("./stop_words.txt", "r") as f:
stop_words = f.readlines()
stop_words = [word.replace("\n", "") for word in stop_words]
# stop words 替换
for i, line in enumerate(sentences):
for word in stop_words:
if word in line:
line = line.replace(word, "")
sentences[i] = line
return sentences
# 分词,将不在词向量中的jieba分词单独挑出来,他们不做分词
def get_words_after_jieba(self, sentences):
# jieba分词
all_exclude_words = dict()
while (1):
words_after_jieba = [[w for w in jieba.cut(line) if w.strip()] for line in sentences]
# 遍历不包含在word2vec中的word
new_exclude_words = []
for line in words_after_jieba:
for word in line:
if word not in self.word2vec_model.wv.vocab and word not in all_exclude_words:
all_exclude_words[word] = 1
new_exclude_words.append(word)
elif word not in self.word2vec_model.wv.vocab:
all_exclude_words[word] += 1
# 剩余未包含词小于阈值,返回分词结果,结束。否则添加到jieba del_word中,然后重新分词
if len(new_exclude_words) < 10:
print("length of not in w2v words: %d, words are:" % len(new_exclude_words))
for word in new_exclude_words:
print word,
print("\nall exclude words are: ")
for word in all_exclude_words:
if all_exclude_words[word] > 5:
print "%s: %d," % (word, all_exclude_words[word]),
return words_after_jieba
else:
for word in new_exclude_words:
jieba.del_word(word)
raise Exception("get_words_after_jieba error")
# 去除不在词向量中的词
def remove_words_not_in_embedding(self, corpus):
for i, sentence in enumerate(corpus):
for word in sentence:
if word not in self.word2vec_model.wv.vocab:
sentence.remove(word)
corpus[i] = sentence
return corpus
# 词向量,建立词语到词向量的映射
def form_embedding(self, corpus):
# 1 读取词向量
w2v = dict(zip(self.word2vec_model.wv.index2word, self.word2vec_model.wv.syn0))
# 2 创建词语词典,从而知道文本中有多少词语
w2index = dict() # 词语为key,索引为value的字典
index = 1
for sentence in corpus:
for word in sentence:
if word not in w2index:
w2index[word] = index
index += 1
print("\nlength of w2index is %d" % len(w2index))
# 3 建立词语到词向量的映射
# embeddings = np.random.randn(len(w2index) + 1, self.embedding_dim)
embeddings = np.zeros(shape=(len(w2index) + 1, self.embedding_dim), dtype=float)
embeddings[0] = 0 # 未映射到的词语,全部赋值为0
n_not_in_w2v = 0
for word, index in w2index.items():
if word in self.word2vec_model.wv.vocab:
embeddings[index] = w2v[word]
else:
print("not in w2v: %s" % word)
n_not_in_w2v += 1
print("words not in w2v count: %d" % n_not_in_w2v)
del self.word2vec_model, w2v
# 4 语料从中文词映射为索引
x = [[w2index[word] for word in sentence] for sentence in corpus]
return embeddings, x
# 预处理,主函数
def process(self):
# 读取原始文件
x, y = self.read_csv_file()
# 错别字,繁简体,拼音,语义不明确,等的处理
x = self.correct_wrong_words(x)
# stop words
x = self.clean_stop_words(x)
# 分词
x = self.get_words_after_jieba(x)
# remove不在词向量中的词
x = self.remove_words_not_in_embedding(x)
# 词向量到词语的映射
embeddings, x = self.form_embedding(x)
# 打印
print("embeddings[1] is, ", embeddings[1])
print("corpus after index mapping is, ", x[0])
print("length of each line of corpus is, ", [len(line) for line in x])
return embeddings, x, y
3.2.2 词向量编码
词向量编码步骤主要有: 加载词向量。词向量可以从网上下载或者自己训练。网上下载的词向量获取简单,但往往缺失特定场景的词语。比如大众点评菜品场景下的鱼香肉丝、干锅花菜等词语,而且往往这些词语在特定场景下还十分重要。而自己训练则需要几百G的语料,在高性能服务器上连续训练好几天,成本较高。可以将两种方法结合起来,也就是加载下载好的词向量,然后利用补充语料进行增量训练。建立词语到词向量的映射,也就是找到文本中每个词语的词向量,对文本进行词向量编码,可以通过keras的Embedding函数,或者其他深度学习库来搞定。 前两步在上面代码中已经展示了,词向量编码代码示例如下
1
2
3
4
5
6
7
Embedding(input_dim=len(embeddings),
output_dim=len(embeddings[0]),
weights=[embeddings],
input_length=self.max_seq_length,
trainable=False,
name=embeddings_name)
3.2.3 构建LSTM网络
LSTM网络主要分为如下几层:
两层的LSTM。
dropout,防止过拟合
全连接,从而可以输出类别
softmax,将类别归一化到[0, 1]之间
LSTM网络是重中之重,这儿可以优化的空间很大。比如可以采用更优的双向LSTM,可以加入注意力机制。这两个trick都可以提高最终准确度。另外可以建立分词和不分词两种情况下的网络,最终通过concat合并。
3.2.4 softmax输出类别
这一部分上面代码已经讲到了,不在赘述。softmax只是一个归一化,讲数据归一化到[0, 1]之间,从而可以得到每个类别的概率。我们最终取概率最大的即可。
3.3 基于深度学习的情感分析难点
基于深度学习的情感分析难点也有很多:
- 语句长度太长。很多用户评论都特别长,分词完后也有几百个词语。而对于LSTM,序列过长会导致计算复杂、精度降低等问题。一般解决方法有进行停用词处理,无关词处理等,从而缩减文本长度。或者对文本进行摘要,抽离出语句主要成分。
- 新词和口语化的词语特别多。用户评论语句不像新闻那样规整,新词和口语化的词语特别多。这个问题给分词和词向量带来了很大难度。一般解决方法是分词方面,建立用户词典,从而提高分词准确度。词向量方面,对新词进行增量训练,从而提高新词覆盖率。